Abstract
Machine learning is increasingly playing a significant role in developing mobile applications such as ADAS, VR and AR, etc. Thus, the hardware architect has designed customized hardware for the machine learning algorithm, particularly for the neural networks, to improve computing efficiency. Still, machine learning is typically just one processing stage in a complex end-to-end application, which involves various components in a mobile system on a chip (SoC). Focusing on machine learning accelerators only loses more extensive optimization opportunities at the system level (SoC). This research paper argues that the hardware architect should expand the scope of optimization to the entire SoC. It is demonstrated by a case study on the domain of continuous computer domain vision. The image signal processor (ISP), Camera sensors, MN accelerators and memory, are synergistically co-designed to achieve the optimal system efficiency level.
Introduction
Mobile devices are currently the most prevalent computing platform and are dominated by ARM architecture. Most of the emerging mobile applications presently rely heavily on machine learning; in precise, various forms of deep neural networks (DNNs) have helped drive the progress on problems such as natural language processing and computer vision. Currently, DNN is typically executing in the cloud on mobile platforms. The trend is to move the execution of DNN from the cloud to the mobile device platforms. This shift is so significant to remove the privacy issues of the cloud offloading approach and communication latency.
The increase in the use of DNN in mobile applications places substantial compute requirement on the system on chip (SoC), which must process billions of linear algebra operations per second with a tight budget of energy. In response, a significant effort has expanded on dedicated hardware to accelerate neural network computation. Tit is borne out during the proliferation of DNN designs for accelerators (MNX), which naturally validates high computation efficiency on the order of 0.4 -3.8TOPS/W on convolutional MN inference [,13,15, 17,19]. This \itis multiple orders of magnitude more efficient than the typical mobile CPU implantation.
Sadly, the benefit of efficiency to the hardware accelerators is essentially a one-time improvement and is likely to saturate, while the requirement for computing of DNNs keeps increasing. Through the use of computer vision as an example, the current convolutional neural (CNN) accelerators are not able to perform the detection of objects (e.g., YOLO [16]) in real-time at 1080p/60fps. Like the frame, resolution rate and the urge for stereoscopic vision grows with VR/AR use cases emergence. The requirement for computing will continue to increase while the power budget remains constant; this leaves a large gap.
Consequently, we must change from a narrow focus hardware accelerator and start considering system-level optimization for machine learning on mobile. Expanding the scope beyond the DNN accelerator to view the whole SoC, we highlight three areas for the optimization:
- System optimization: co-design of algorithms and the various hardware blocks in the system.
- Accelerator interfacing: Hardware accelerators must be interfaced efficiently with the rest of the SoC to achieve the full benefit.
- The software Abstractions: for the cross-platform compatibility, the details of the SoC should be abstracted using a clean API
Machine Learning on Mobile Systems.
We have already started seeing changes in mobile systems in response to the computational demand for deep learning methods. Most remarkably, the MNX components are now standard in mobile SoCs. For example, the natural engine in iPhone [2] and the HPU CNN co-processors in the Microsoft HoloLens [7]. But a significant challenge remains on how to integrate the
components of the MNX into the system. This paper identifies three aspects from both the software and hardware perspectives.
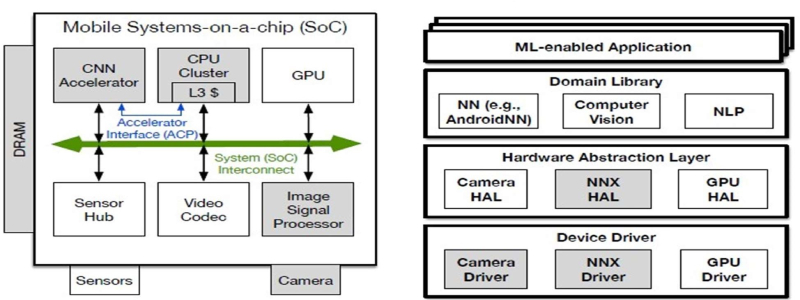
Software abstraction: the hardware of mobile SoC and the machine learning algorithm are both rapidly evolving. Therefore, presenting the programming interface that minimizes the disruption to application developers is paramount. This would provide compatibility across a wide range of Mobile Soc and make the new hardware features easy. The key to such a programming interface is an evident abstraction that allows the applications to execute jobs related to DNN efficiently on (one of many) hardware accelerators. The android NN API provides the perfect example of this principle through abstracting a standard DNN kernel, such as scheduling the execution through the abstraction of hardware layer (HAL) and convolution.
Optimized implementation for the DNN kernel is provided in the form of an ARM compute library. The library takes advantage of the recent enhanced ARM ISA that provides the new instructions for the linear algebra operation, which are essential behind DNNs, such as the new dot product instruction found on the NEON SIMD extension. Lastly, the specific IP drivers are provided and the implementation of HAL to support the android-NN API.
Accelerator interfacing: There exist two challenges in the interfacing NNX Ips to the rest of the mobile hardware system. It provides sufficient bandwidth memory for weight and activation data and provides an efficient path to offload the NN task from the CPU to the NNX. Specifically, the memory interface between the SoC and the accelerator is essential because the modern DNN typically has parameters that have large sets that demand high memory bandwidth to feed the units of the arithmetic.
The critical insight is to leverage the L3 cache in cluster CPU as the bandwidth filter and not directly interface the DRAM, and the NNX as some state-of-the-art NNX designs currently do. It is attained through the ARM accelerator Coherency port (ACP), which exists on the cluster CPU and allows the attached accelerators to load and store data directly to and from the L3. This way, the NNX also takes advantage of the L3 cache features in the CPU clusters, such as cache stashing, partitioning, and prefetching. Additionally, the Accelerator coherency port is also low latency such that the NNX and CPU can collectively work closely on data in the L3 cache.
System optimization: when adding specialized NNX hardware IP to the SoC improves the efficiency and performance of the kernel, the components of the DNN are typically only one stage in a sizeable end-to-end application pipeline. For example, in computer vision, many off/ on chips components such as sensors, cameras, image signal processors (ISP), NNX and DRAM memory have to collaborate to deliver real-time vision capabilities. The IP of the NNX constitutes at most half of the total energy/ power consumption, and there are additional opportunities in jointly optimizing the whole system.
Once the scope is expanded to the system level, new optimization opportunities are exposed by exploiting the functional synergies across different Ip blocks; these optimizations are not obvious, even though NNX is in isolation. This principle is demonstrated in the following case study.
Case Study. (Continuous Vision).
Computer vision tasks such as localization, tracking, and classification are critical capabilities for most exciting new application domains on mobile devices, such as virtual reality (VR) and augmented reality (AR). However, the cost of the modern computational computer vision CNNs far exceeds the severely limited power budget of mobile devices, particularly for real-time (example, 1080/60fps). This is true even with a dedicated CNN hardware accelerator [13,15,15,19].
Complete the real-time object detection with high accuracy on mobile devices; the idea is to reduce the total number of expensive CNN inferences through the optimization system level. This is done through harnessing the synergy between the different IPs hardware of the vision subsystem. Specifically, the image signal processor (ISP), which inherently calculates the motion vectors (MV) for use in its temporal denoising algorithm, is leveraged. Usually, the motor vector is discarded, but we elect and expose them at the system level. Instead of using the CNN inference on every frame to track the object movement, we reuse the motor vector to extrapolate the object movement detected in the previous video frame. As we increase the number of the consecutively figured frames, the total number of CNN inferences is reduced, which leads to energy improvement and performance.
We can also leverage the ACP and the ARM interface to use the LLC for the inter-layer data reuse (for example, the feature maps), which would otherwise be spilt by the DRAM from the NN accelerator local SCRAM. An L3 typical size in mobile devices is about 2mbs, and the ACP provides about 20GB of bandwidth, which is enough to capture the reuse of most of the layers in present object detection CNNs. This design dramatically reduces the DRAM and the power consumption of the system.
Lastly, software that supports the abstracts away the implementation of the hardware details presented. An example is shown by fig 1, where the high-level computer vision libraries are unmodified, which keeps the android-NN interface unchanged. A specific driver and the modification of HAL implemented that the hardware augmentation entails.
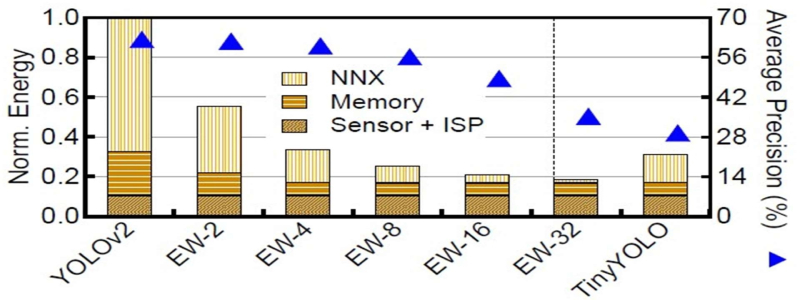
A system-level optimization was evaluated on an in-house SoC simulator, calibrated with the measurement of the Jetson TX2 development board. A commonly used benchmark was used, such as the VOT and the OTB and the internal dataset. Outcomes in figure 2 show that compared to state-of-the-art object detection frameworks such as YOLO that executes an entire CNN for every frame, the system reduces the energy by over 40% with less than 1% accuracy loss of extrapolation window size of the two. The energy-saving is more significant as the extrapolation window increases while the accuracy reduces. Compared to the conventional approach of reducing the intensity of computing by downscaling the network (for example, YOLO, which is 5⁓ × simpler), the system achieves higher accuracy and higher energy saving.
Conclusion
Efferently supporting the demanding machine learning workload on energy-constrained mobile devices requires careful attention to the overall system design. The paper emphasized the three key research priorities: Cross Ip optimization, software abstraction, and accelerator interfacing. The mobile Machine learning Hardware at ARM: system on chip
Bibliography
- [n. d.]. Apple’s Neural Engine Infuses the iPhone With AI Smarts. ([n. d.]). https://www.wired.com/story/.
- [n. d.]. Android Neural Networks API. ([n. d.]). https://developer.android.com/ and /guides/neural networks/index.html apples-neural-engine-infuses-the-iPhone-with-smarts/
- [n. d.]. ARM Accelerator Coherency Port. ([n. d.]). http://infocenter.arm.com/ help /index.jsp?topic=/com.arm.doc.ddi0434a/BABGHDHD.html.
- [n. d.]. Visual Tracker Benchmark. ([n. d.]). http://cvlab.hanyang.ac.kr/tracker_ benchmark/datasets.html.
- Vijay Janapa Reddi and Matthew Halpern, Yuhao Zhu, (2016). Mobile CPU’s Rise to Power: Quantifying the Impact of Generational Mobile CPU Design Trends on Performance, Energy, and User Satisfaction. In Proc. of HPCA.
- [n. d.]. Jetson TX2 Module. ([n. d.]). http://www.nvidia.com/object/ embedded-systems- dev-kits-modules.html.
- [n. d.]. Second Version of HoloLens HPU will Incorporate AI Coprocessor for Implementing DNNs. ([n. d.]). https://www.microsoft.com/en-us/research/blog/ second-version-hololens-hpu-will-incorporate-ai-coprocessor-implementing-dnns/
- Santosh Divvala,] Joseph Redmon, Ali Farhadi, and Ross Girshick, (2016). You Only Look Once: Unified, Real-Time Object Detection. In Proc. of CVPR.
- [n. d.]. Arm Compute Library. ([n. d.]). https://github.com/ARM-software/ComputeLibrary.
- Yu-Shin Chen, Joel Emer, and Vivienne Sze. 2016. Egersis: A Spatial Architecture for Energy-efficient Dataflow for Convolutional Neural Networks. In Proc. of ISCA


Comments